记录一下最近研究知识图谱的收获,主要从从表示学习,知识获取,知识应用三个角度对知识图谱领域进行说明,整体框架主要参考了 A Survey on Knowledge Graphs: Representation, Acquisition and Applications.
最近深度学习模型特别是基于deep transformer的预训练语言模型在NLP的各个领域取得了卓越的效果,开启了NLP的新时代。但是这些模型往往缺乏事实知识(Factual knowledge),而事实知识作为一先验信息往往在自然语言理解中起重要作用。如何表示知识?如何将知识引入到模型?知识图谱作为一种直观的表示方式,将知识描述为三元组的形式。这种symbolic描述方式符合人对知识的直观感受,具备一定的知识表示能力和推理能力,但是难以和neural model结合。这就引出了知识表示学习(Knowledge Representation Learning),通过从知识图谱学习得到entity和relation的embedding,将知识融入到现有的neural model框架之下。KRL的关键是如何评估三元组的plausibility,建模为scoring function的设计问题。主要可以分为translational distance model和semantic matching model两类。前者将关系视为头实体到尾实体的某种空间变换,采用某种距离度量衡量plausibility,后者则是利用神经网络对语义相似度进行建模。
现有的大型知识图谱,其构建过程依赖于结构或半结构数据,需要大量的人工介入,存在稀疏问题,我们希望能自动化地从非结构化文本数据中构建知识图谱,这就引出了知识获取(Knowledge Acquisition)。KA可以分为图谱补全、实体发现、关系抽取三部分。图谱补全任务依赖于已有知识去预测补全三元组,模型主要有embedding-based和rule-based两类。embedding-based方法的基本思路是利用scoring function对候选实体进行排序,选取score最高的候选实体,模型采用负采样技术进行训练。rule-based方法对path建模并进行path searching补全图谱。前者有较强的特征表示能力,后者有较强的推理能力,如何将二者的优势结合也是重要的研究方向。基于GNN(GCN、GAT)的方法在现有数据集上取得了SOTA的效果。实体发现可以分为实体识别、实体分类、实体连接三部分。实体识别任务从文本中识别出entity的boundry和type,实体分类对mention进行更细粒度的分类,实体连接将文本中的entity mention对应到知识图谱中的某一entity上。关系抽取方面,为了解决关系的长尾分布特点导致的数据稀疏问题,提出了远程监督(Distant Supervision)方法。该方法借助知识库中已有的事实三元组对文本进行标注。远程监督较强的假设会导致数据的错误标注,因此提出了多示例学习(Multi-instance Learning)缓解这一问题。实体描述和关系别名也常被引入关系抽取模型中以提高模型表现。
知识图谱如何赋能NLP也是研究的热点。在预训练模型上引入知识的工作如ERNIE,K-BERT,KEPLER等,通过在已有模型中加入entity embedding输入或者objective function约束来引入知识。QA方面,部分工作将问题转化为图谱上的查询语句实现问答系统。推荐系统方面,部分工作通过引入知识图谱中商品的知识来解决传统协同过滤中数据稀疏和冷启动的问题。
知识图谱定义
知识图谱可以看做是知识库的代名词,其差异很小。在考虑其图形结构时,知识图谱可以看作是图。
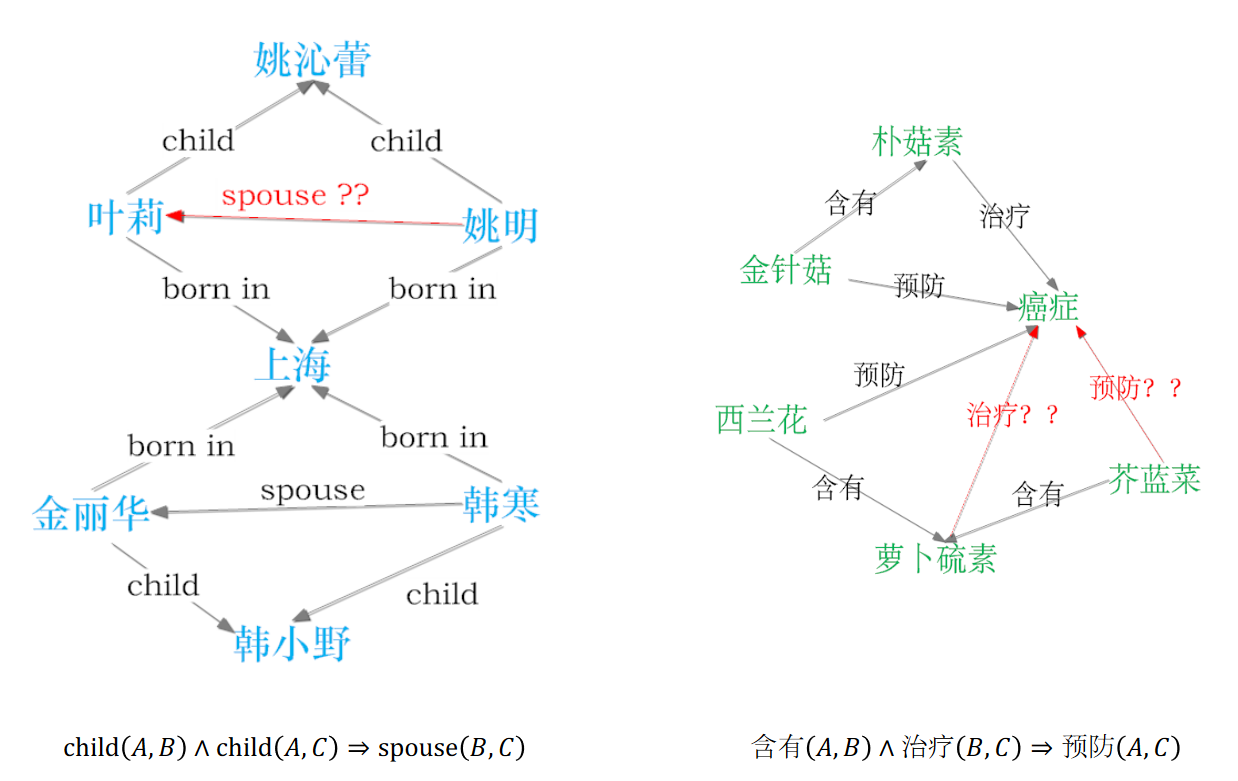
有向,多关系的知识图谱可以通过一个三元组来表示(head, relation, tail)
知识图谱的概览
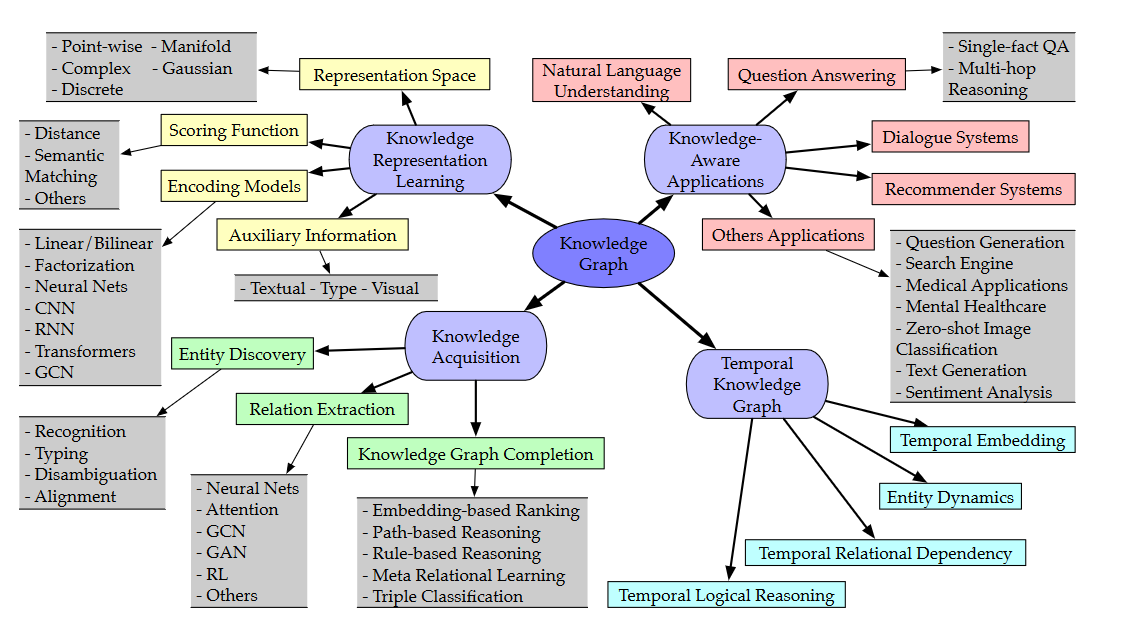
知识表示
一个知识表示是事物本身的一个替代,使得我们可以通过思考而不是行动来确定事物的后果 吃饭会饱(不需要每次都吃来确认),冰岛是一个国 家(虽然没去过)
一个知识表示是一个本体约定集合,它回答如下问题:我们该 用什么术语(terms)来思考这个世界?
知识表示框架
Freebase
Freebase 的知识表示框架主要包含如下几个要素:对象-Object、事实-Facts、类型-Types和属性-Properties。Object代表实体。每一Object有唯一的ID,称为 MID(Machine ID)。一个Object可以 有一个或多个Types。Properties用来描述Facts。
Wikidata
Wikidata的知识表示框架主要包含如下要素:页面-Pages、实体Entities、条目-Items、属性-Properties、陈述-Statements、修饰Qualifiers、引用-Reference等
ConceptNet ConceptNet5的知识表示框架主要包含如下要素:概念-Concepts、 词-Words、短语-Phrases、断言-Assertions、关系-Relations、边-Edges
知识表示过程
前面提到的知识图谱的表示方法中,其基础大多是以三元组的方法对知识进行组织。虽然这种离散的符号化的表达方式可以非常有效地将数据结构化,但这些符号并不能在计算机 中表达相应语义层面的信息,也不能进行语义计算,对下游的一些应用并不友好。
为了解决前面提到的知识图谱表示的挑战,在词向量的启发下,研究者考虑如何将知识图谱中的实体和关系映射到连续的向量空间,并包含一些语义层面的信息,可以使得在下游任务中更加方便地操作知识图谱,例如KBQA、关系抽取等。对于计算机来说,连续向量的表达可以蕴涵更多的语义,更容易被计算机理解和操作。把这种将知识图谱中包括实体和关系的内容映射到连续向量空间方法的研究领域称为知识图谱嵌入(Knowledge Graph Embedding)、知识图谱的向量表示、 知识图谱的表示学习(Representation Learning)或者知识表示学习。
知识表示学习过程主要有4个过程,知识的空间表示,评分函数,编码模型,附加信息嵌入。
1. 表示空间
表示学习的关键问题是学习实体和关系低维分布式嵌入空间。在这里主要采用的是point-wise space、complex vector space、Gaussian space、Manifold and Group space。point-wise space是使用最多的,以翻译模型TransE和其变种模型TransX系列为代表,遵循h(头实体) + r(关系) ≈ t(尾实体) 的原则。complex vector space的代表模型是plEx、RotatE以及QuatE。Gaussian space是受到高斯分布的启发,以KG2E、TransG为代表性模型。Manifold流形是一个拓扑空间,也是为了解决point-wise space中的嵌入问题,以ManifoldE、TorusE和DihEdral为代表性模型。几种表示空间如下图所示(图来源于原论文)。
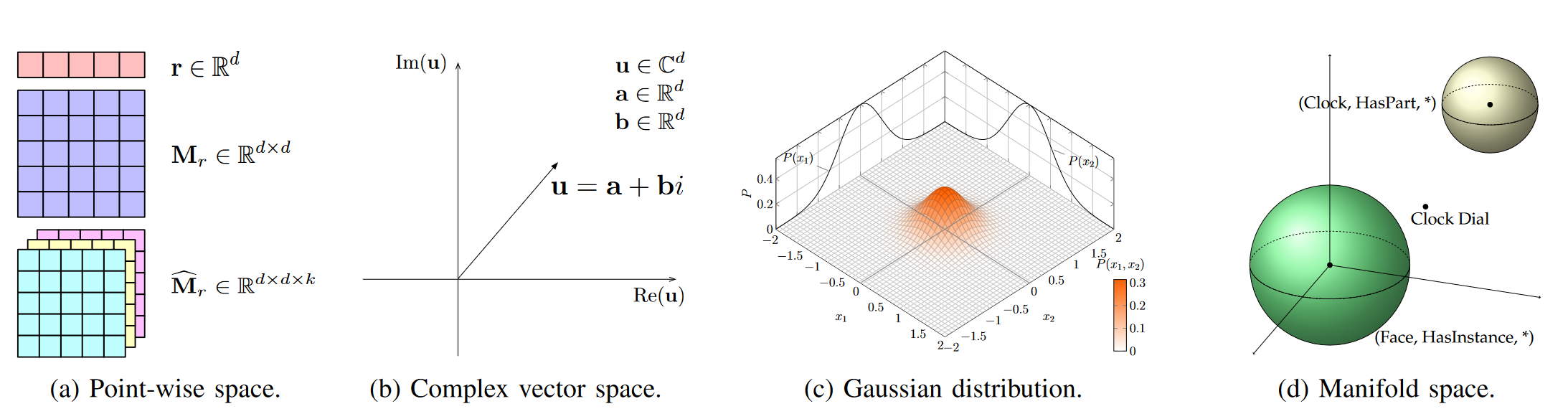
嵌入空间应遵循三个条件,计算的可能性,计算可能性以及评分函数的确定性
欧几里得空间的角度广泛用于表示实体和关系,将实体或关系投影嵌入到向量或矩阵空间中来获取相关关系。
2. 评分函数
评分函数用于衡量事实的合理性,有两种典型的评分函数类型,即基于距离(图4A)和基于相似性的功能(图4B)函数,以衡量事实的合理性。
基于距离的评分函数通过计算实体之间的距离来衡量事实的合理性,基于加法的公式$h + r \approx t$被广泛使用。 基于语义相似性的评分通过语义匹配来衡量事实的合理性。它通常采用乘法公式$h^{T}M_r \approx t_T$,来衡量头部实体和尾部实体在表示空间中的距离。
基于距离的评分函数
-
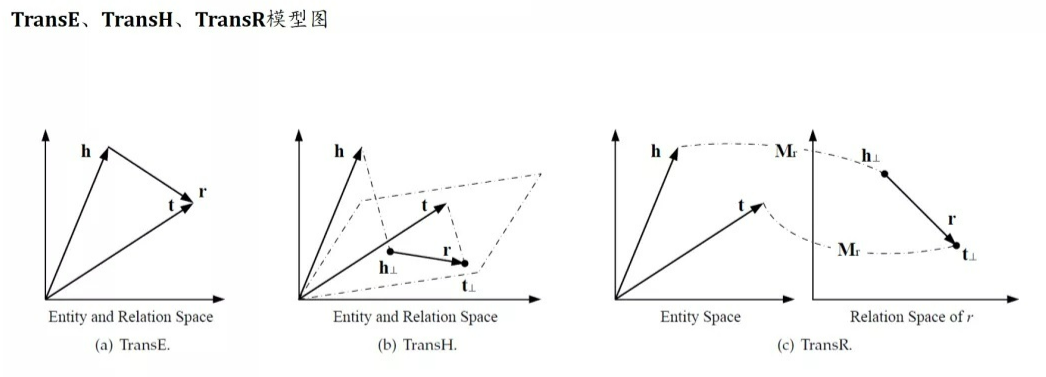
TransE: 三元组h,r,t都在同一个向量,方法简单有效,但缺点是没法处理1-N,N-1, N-N的多关系知识图谱,因此需要Relation-Specific Entity Embeding \(f_r{(h,t)} = -\left \| h+r-t \right\|_{1/2}\)
-
TransH: TransH模型引入了Relation-Specific超平面。将实体h和t沿着发现$w_r$映射到关系r对应的超平面上,得到$h_{ \perp},t_{\perp}$, 再使用TransE的scoring functions,这样可以让一个实体在不同的关系下拥有不同的表示,解决了TransE无法解决1-N,N-1, N-N的多关系问题 \(h_{\perp} = h-w_{r}^{T}hw_{r}, t_{\perp}=t-w_{r}^{T}hw_{r}, f_{r}{(h,t)}=-\left \| h_{\perp}+r-t_{\perp} \right\|_{2}^{2}\)
-
TransR: TransR和TransH不同之处在于,TransR是使用Ralation-Specific space代替了TransH的超平面,每一个关系r关联一个特定的空间,首先需要将实体映射到关系空间上,映射方式利用一个实体空间到关系空间的一个投影矩阵。 \(h_{\perp}=M_{r}h, t_{\perp}=M_{r}t\) 这种解决方式也引入了一个问题,转换方式是空间矩阵投影,复杂度高 \(f_{r}{(h,t)}=-\left \| h_{\perp}+r-t_{\perp} \right\|_{2}^{2}\)
-
TransD:TransR每个关系对应一个投影空间,因此每个关系r需要引入一个投影矩阵$W_r$, 导致参数量巨大,而TransD便是对TransR的简化,TransD将TransR的投影矩阵分解成两个向量的积,从而降低了参数量 \(M_{r}^{1}=w_{r}w_{h}^{T}+I, M-{r}^{2}=w_{r}w_{t}^{T}+I, h_{\perp}=M_{r}^{1}h, t_{\perp}=M_{r}^{2}t\)
-
TransSparse: TransSparse也是对TransR的一种改进, 在投影矩阵上强化稀疏性来简化TransR,
-
TransM: 放低了TransE的$h+r=t$的要求,提高模型性能,为每个事实分配特定的关系权重,通过对1-N,N-1,N-N分配较低的权重,TransM使t在复杂关系中离h+r更远, \(f_{r}(h,t)=-\theta_{r} \left \| h+r-t \right\|_{1/2}\)
-
MianfoldE: 将$h+r\thickapprox t$放宽到$\left | h+r-t \right|{2}^{2} \thickapprox \theta{2}^{2}$, scoring functions \(f_{r}{(h,t)}=-(\left \| h+r-t \right\|_{2}^{2} - \theta_{2}^{2})^{2}\)
-
TransF: 也是放低了TransE的$h+r=t$的要求, 只要求h+r的方向和t的方向一致,同时t-r的方向和h的方向也一致,scoring functions: \(f_{r}{(h,t)}=(h+r)^{T}t+(t-r)^{T}h\)
-
TransA: 为每个关系r引入一个对称的非负矩阵Mr,使用自适应马氏距离定义评分函数 \(f_{r}{(h,t)}=-(|h+r-t|^{T}M_{r}(|h+r-t|))\)
基于距离的评分函数(高斯嵌入)
考虑实体和关系的不确定性,因此可以用随机变量进行建模
-
KG2E: 使用高斯分布表示实体和关系,高斯分布的均值表示实体或关系在语义空间的中心位置,而高斯分布的协方差则表示改实体或关系的不确定性,KG2E模型将实体和关系表示为多变量高斯分布中抽样取得随机变量。通过测量t-h和r这两个随机变量之间的距离来为一个事实评分,通过这两种方式进行测量。一种是通过KL散度, 一种是计算概率的内积 \(h \sim N(\mu_{h}, \sigma_{h}^{2}I), t \sim N(\mu_{t}, \sigma_{t}^{2}I)\)
-
TransG: 实体采用高斯分布,但认为关系具有多重语义, 采用混合高斯分布来表示 \(r=\sum_{i}\pi_{r}^{i}\mu_{r}^{i}, \mu_{r}^{i} \sim N(\mu_{t}-\mu_{h}, (\sigma_{h}^{2}+\sigma_{t}^{2})I)\) \(f_{r}(h, t)=-\left \| h-t \right\|_{2}^{2}\)
语义匹配模型(基于相似度的评分函数)
-
RESCAL: 双线性模型, 实体用向量表示, 关系用矩阵表示,关系矩阵对潜在因素之间的成对交互作用进行建模,评分函数就是一个双线性函数 \(f_r(h,t)=h_TM_rt=\sum_{i=0}^{d-1}\sum_{j=0}^{d-1}|M_r|_{ij}\cdot|h|_i|t|_j\)
-
DistMult: 对RESCAL进行简化,将关系矩阵改成对角矩阵,对每条边r引入vector embeding, 从而得到对角矩阵$M_r=diag(r), 但是DistMult只能处理对称关系,对于一般的kGs不适用$ \(f_r(h,t)=h^Tdiag(r)T=\sum_{i=0}^{d-1}|r|_i\cdot|h|_i\cdot|t|_i\)
-
HoLE: 结合了RESCAL的表达能力和DistMult的计算性能,引入了一个circular correlationo f embeding.可以解释为压缩张量学习,对应的打分函数为 \(f_r(h,t)=r^T(h * t)\)
3. 编码模型
线性模型通过线性/双线性的映射方式,将head实体映射到表征空间,使其接近tail实体。因子分解机通过将关系数据分解到低秩矩阵进行表征学习。神经网络使用非线性神经激活的方式或者更复杂的网络结构编码关系数据
线性/双线性模型
线性和双线性模型通过简单的乘法操作编码实体和关系的交互。线性和非线性的表示为 \(g_r(h,t)=M_r^T\left(x y \right)\)
分解模型 将关系数据分解成低维矩阵进行表征
神经网络学习 通过学习实体和关系的语义相似性,对具有非线性神经激活和更复杂网络结构的关系数据进行端到端地编码。包括CNN,RNN, transformer等方法
4. 基于附加信息的嵌入模型
除了依靠知识库中的三元组构建知识图谱的嵌入模型,还有一些模型额外增加了附加信息,如文本描述, 适宜类型,相关路径,可视化信息等。
