前言
客流量是规划铁路客运系统的基础,科学合理地客流预测能够辅助客运部门规划与管理客运运营,从而提升运营收益、降低风险。自新冠肺炎疫情爆发以来,严重影响了国家铁路运输的正常运营,对铁路客运发展的短期影响最为显著[1]。2020年上半年,全国铁路发送旅客8.18亿人次,同比下降53.9%[2],随着我国进入“后疫情时代”,铁路客流逐步回升,客流准确预测显得愈发重要。 目前,国内关于铁路客流预测已有不少的研究,采用的方法主要包括:灰色预测法[3-4]、支持向量回归机[5-6]、组合预测法[7]等。这些研究和方法各有优势,针对的预测对象也有所不同,但在样本数据集选择方面,极少有研究使用新冠肺炎疫情期间的铁路客流数据进行预测;同时新冠肺炎疫情期间的铁路客流数据存在较大的波动性和随机性,对提高预测的准确性增加了难度。
本文采用极端梯度提升(XGBoost,eXtreme Gradient Boosting)模型,以上海站为例,选用包含新冠肺炎疫情期间的样本数据,研究将极端梯度提升模型应用于预测铁路大型客运站客流量的效果
XGBoost模型概述
XGBoost是Exterme Gradient Boosting(极限梯度提升)的缩写,它是基于决策树的集成机器学习算法,它以梯度提升(Gradient Boost)为框架。XGBoost是由由GBDT发展而来,同样是利用加法模型与前向分步算法实现学习的优化过程,但与GBDT是有区别的。主要区别包括以下几点:
- 目标函数:XGBoost的损失函数添加了正则化项,使用正则用以控制模型的复杂度,正则项里包含了树的叶子节点个数、每个叶子节点权重(叶结点的socre值)的平方和。
- 优化方法:GBDT在优化时只使用了一阶导数信息,XGBoost在优化时使用了一、二介导数信息。
- 缺失值处理:XBGoost对缺失值进行了处理,通过学习模型自动选择最优的缺失值默认切分方向。
- 防止过拟合: XGBoost除了增加了正则项来防止过拟合,还支持行列采样的方式来防止过拟合。
- 结果:它可以在最短时间内用更少的计算资源得到更好的结果。
XGBoost被广泛应用于机器学习领域。
XGBoost的基学习器
XGBoost的可以使用Regression Tree(CART)作为基学习器,也可以使用线性分类器作为基学习器。以CART作为基学习器时,其决策规则和决策树是一样的,但CART的每一个叶节点具有一个权重,也就是叶节点的得分或者说是叶节点的预测值。CART的示例如下图:
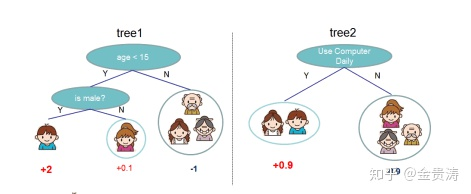
图中为两颗回归树(左右两个),其中树下方的输出值即为叶节点的权重(得分),当输出一个样本进行预测时,根据每个内部节点的决策条件进行划分节点,最终被划分到的叶节点的权重即为该样本的预测输出值。
XGBoost的模型XGBoost模型的定义为:给定一个包含n个样本m个特征的数据集 $|D| = {(x_1, y_1), (x_2, y_2)…(x_n, y_n)}$ ,集成模型的预测输出表示为: $\hat{y_i}=\sum_{k=1}^{K}f_k(x_i)$ (1)
其中$f_k$表示第k颗回归树,K为回归树的数量,整个式(1)表示给定一个输入$x_i$输出值为K颗回归树的预测值。
模型学习
通常情况下,怎样去学习一个模型?
定义目标函数,即损失函数以及正则项。 优化目标函数。 按照这个套路,第一步定义XGBoost的目标函数。
$L(\phi) = \sum_{k}\iota(\hat{y_i}, y_i) + \sum_{k}\Omega(f_k)$ (2)
| $\Omega(f_k)=\Gamma T + \frac{1}{2}\lambda | w | $ |
其中,$\iota(\hat{y_i}, y_i)$ 表示第$i$颗树的模型误差,$\Omega(f_k)$ 代表模型复杂度。$T$ 表示叶子结点个数,γ和λ表示惩罚项的权重参数。
铁路客流波动特征及影响因素
日期属性对客流的影响
铁路客流的短期变化受多方面的因素影响,并呈现出特定的规律性。分别以周和月为周期分析客流的情况。
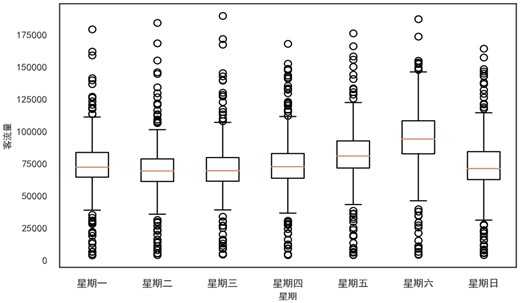
如图4所示,周六客流人数在一周中最高,周五其次,其他无显著差异。进一步分析节假日对客流的影响情况,如图5所示,节假日相比工作日客流人数有明显的增加,节假日前一天的客流人数不仅显著高于工作日的客流人数,并且略高于假期的平均客流人数,
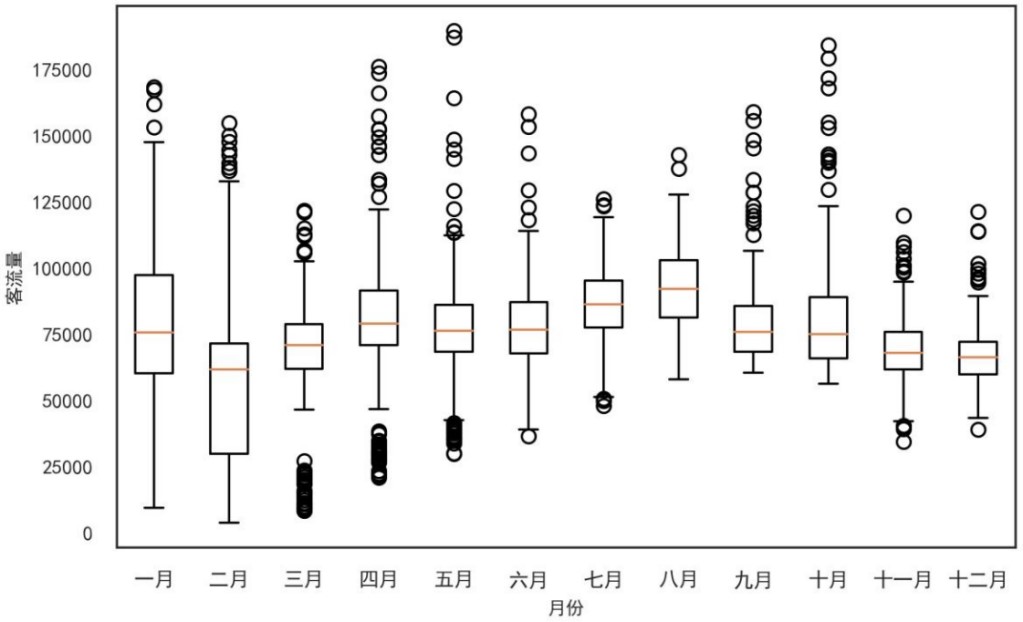
以月份为单位观察发现,因受暑假以及适宜的天气影响,夏季8月份的客流规模高于同期其他月份,而在天气最寒冷的二月客流规模相对最低。
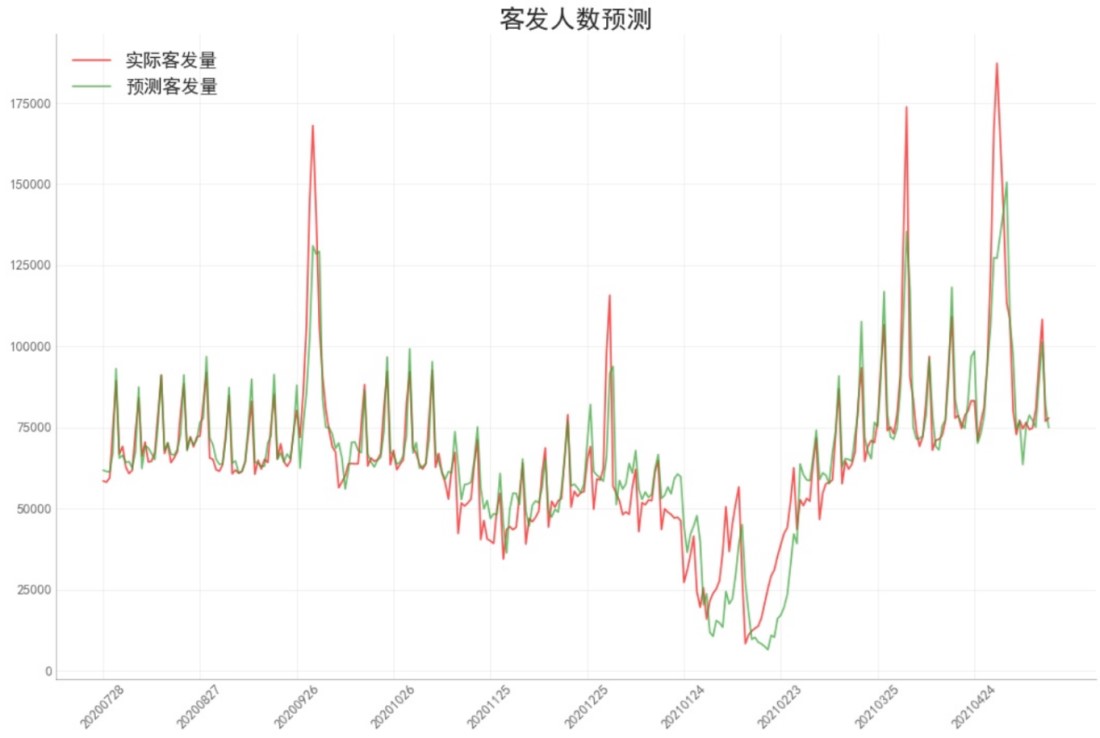
试验结果
在模型训练过程中,取前85%的数据划分为训练和验证样本,后15%的数据作为测试样本。
首先将细分后的日期属性特征进行预处理,对月份、星期进行One-hot编码,对假期进行哑编码,并将编码后的数据转化为有监督的数据集;
其次考虑到当日客流量除了会受到同期因素的影响,还可能与它前期值有关,故采用自身滞后变量作为特征;
为了消除预测的随机波动,利用简单移动平均法生成前五天平均客流量和前十天平均客流量作为特征。
最后预处理后的有监督数据集输入列数为36列,输出列数为1列。考虑到样本容量较小,在模型训练阶段,采用了k折交叉验证进行训练,提升模型的性能,本文取k=5